
Visual Grounding of Sound and Language
From : Mark Hamilton, Andrew Zisserman, John R. Hershey, William T. Freeman
// English
Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
Abstract
We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters.
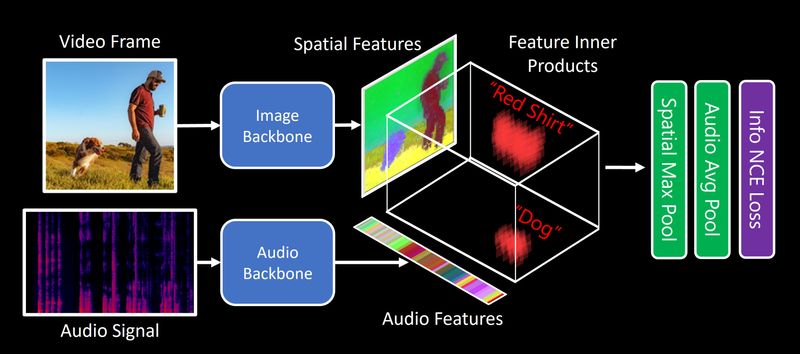
Audio-Video Contrastive Learning
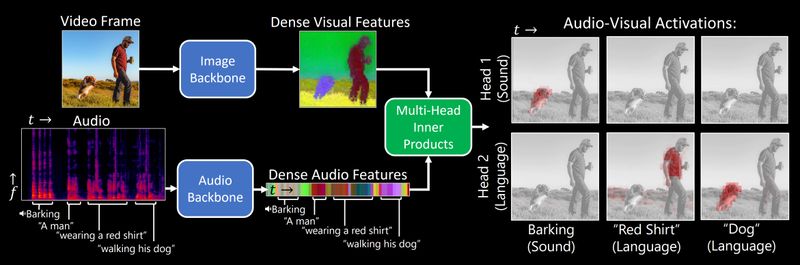
DenseAV can learn the meaning of words and the location of sounds using only self-supervision from video. To learn these patterns, DenseAV uses audio-video contrastiv learning to associate sound with the visual world. Intuitively speaking, its much easier to predict what you are seeing from what you are hearing when you understand language and can recognize sounds. This is how DenseAV can learn without labels.

Most Contrastive Learners Cannot Localize Sound or Language
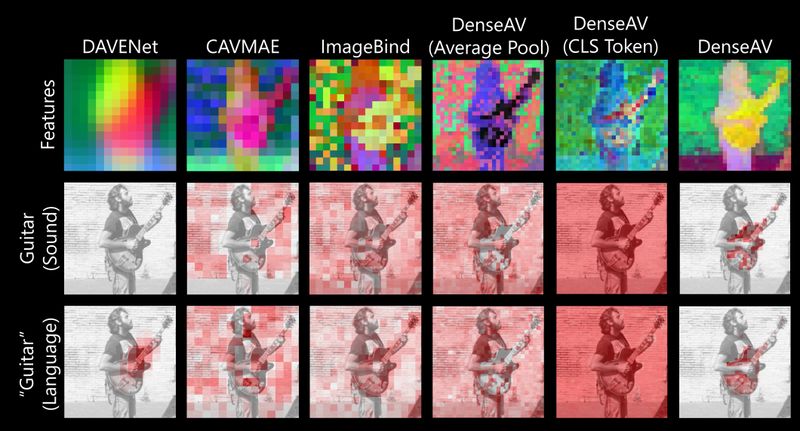
Interestingly, contrastive learning with CLS tokens or average pooled representations isnt enough to be able to localize objects from sound and language. DenseAV uses a contrastive similarity based on inner products between local audio and visual representation tokens. This dramatically improves its ability to localize information.
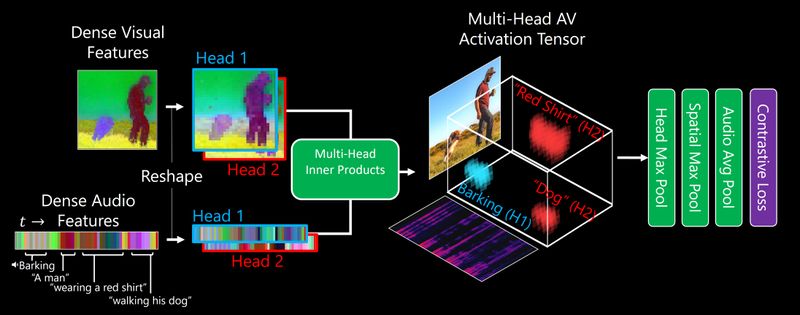
Unsupervised Disentanglement of Sound and Language

Theres many ways that a sound can be related to an visual object. For instance, the word "dog" and the sound of a bark both conjure the image of a dog despite being very different types of sound. In an analogy with multi-head attention we provide DenseAV with multiple features to compute inner products with. Amazingly, DenseAV naturally organizes it's features into sound-features and language features without knowing a-priori what is sound and what is language.
Source : https://mhamilton.net/denseav
Demo : DenseAV - a Hugging Face Space by mhamilton723
PAPER



Comments (1)
Hitech BPO
09, Apr 2026If you are looking to get data augmentation or annotation on such data then this is your exit : https://www.hitechbpo.com/b2b-data-solutions.php
https://www.hitechbpo.com/llm-training-data-services.php